I don't think it is a good idea technically or politically for FreeBSD 12.0 to ship without this (phoronix etc)
Details
Details
Diff Detail
Diff Detail
- Repository
- rS FreeBSD src repository - subversion
- Lint
Lint Not Applicable - Unit
Tests Not Applicable
Event Timeline
Comment Actions
We've had it in our config at Netflix for so long that I forgot that it was not in GENERIC..
Comment Actions
With the NUMA option enabled ZFS hangs after a few minutes of heavy write load causing the deadman switch to panic the kernel on a 32 core AMD EPCY 7551P. I can still write to the swap partitions on the same disks while writes to ZFS on an other partition hang.
Comment Actions
Which deadman switch: software watchdog, deadlkres, ...? If you're able to get a kernel dump, would you be willing to share it with us? If not, and you're able to run ddb commands, it would be useful to see the output of the commands listed here: https://www.freebsd.org/doc/en/books/developers-handbook/kerneldebug-deadlocks.html
Finally, I'd appreciate it if you'd report the problem on freebsd-current so that folks can easily chime in with a "me too".
Comment Actions
It seems like this might also be a result of the bug in balanced pruning. Have you retried since the default was changed?
Comment Actions . Ignore the nvme related lines. I reproduced the same panic with them unplugged. I used the ALPHA5 memstick (r338518) to install and encountered the panic with the GENERIC kernel from that installation. I checked out r338638 which includes NUMA in GENERIC and compiled a GENERIC-NODEBUG kernel and disabled malloc debugging to get a realistic impression of the hardware's potential. The EPYC system compiled the kernel and world just fine so I attached and imported the old ZFS pool from its predecessor (a FreeBSD 11.2 system) and tried to send | recv the relevant datasets from the old pool to a new pool. This repeatedly hung after about 70-80GB. Until writes stopped the system transferred 1.0 to 1.1GB/s. I remembered reading about starvation in the NUMA code disabled it on a hunch. With NUMA disabled the system is stable (so far) and currently half way through copying 107TB from the old pool to the new pool.
. Ignore the nvme related lines. I reproduced the same panic with them unplugged. I used the ALPHA5 memstick (r338518) to install and encountered the panic with the GENERIC kernel from that installation. I checked out r338638 which includes NUMA in GENERIC and compiled a GENERIC-NODEBUG kernel and disabled malloc debugging to get a realistic impression of the hardware's potential. The EPYC system compiled the kernel and world just fine so I attached and imported the old ZFS pool from its predecessor (a FreeBSD 11.2 system) and tried to send | recv the relevant datasets from the old pool to a new pool. This repeatedly hung after about 70-80GB. Until writes stopped the system transferred 1.0 to 1.1GB/s. I remembered reading about starvation in the NUMA code disabled it on a hunch. With NUMA disabled the system is stable (so far) and currently half way through copying 107TB from the old pool to the new pool.
I attached a screenshot of the system console taken via IPMI
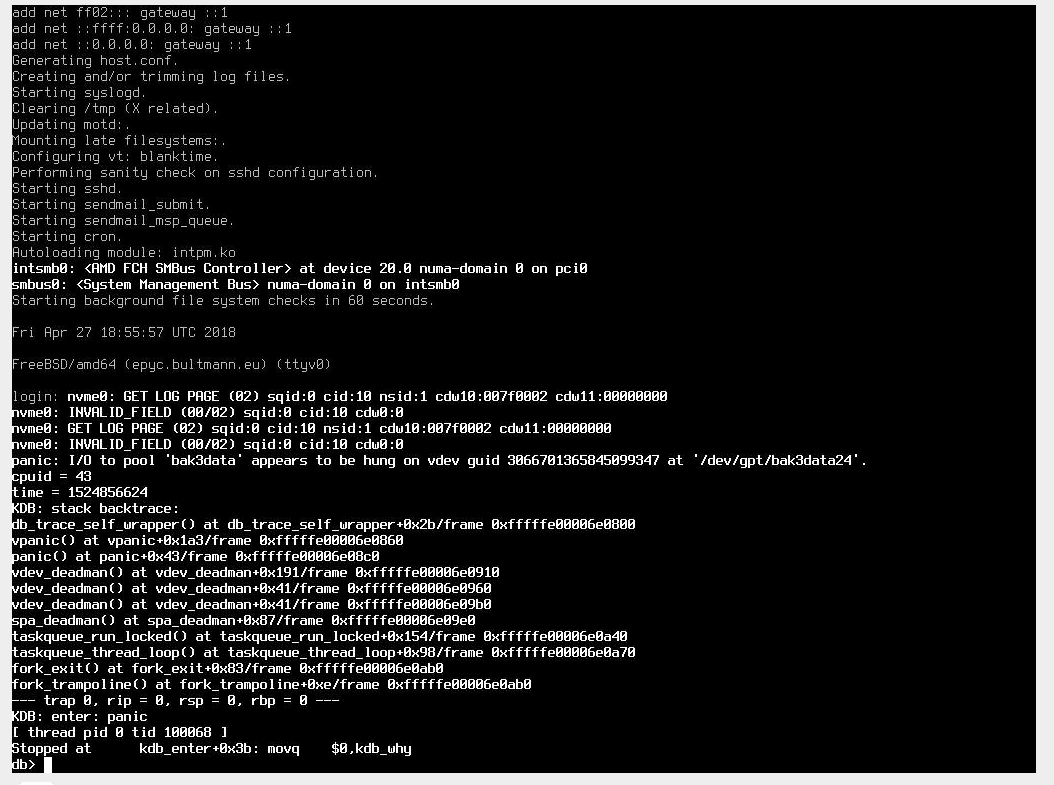
Comment Actions
Thanks. I think we'll need to see "alltrace" and "show page" output in order to make progress.
Comment Actions
After copying 110TB between two pools with zfs send | mbuffer -m1g -s128k | zfs recv on a kernel without "options NUMA" I bootet a kernel with "options NUMA" build from revision 338698. ZFS writes still hang, but the system doesn't panic. The mbuffer output shows that the buffer remains 100% full when writes hang.
Comment Actions
Never mind. The ghosts in the machine read my post. The kernel just panic()ed again. I'm at the kernel debugger prompt in the IPMI KVM webinterface.
Comment Actions
I gave up after >500 screenshots of the IPMI KVM output. I haven't yet found a working configuration for the Serial over LAN. I'm trying again with a dump device large enough to hold >200GB RAM.
Comment Actions
This time I triggered a panic via sysctl a few minutes after ZFS writes hung but before the kernel panic()ed on its own.
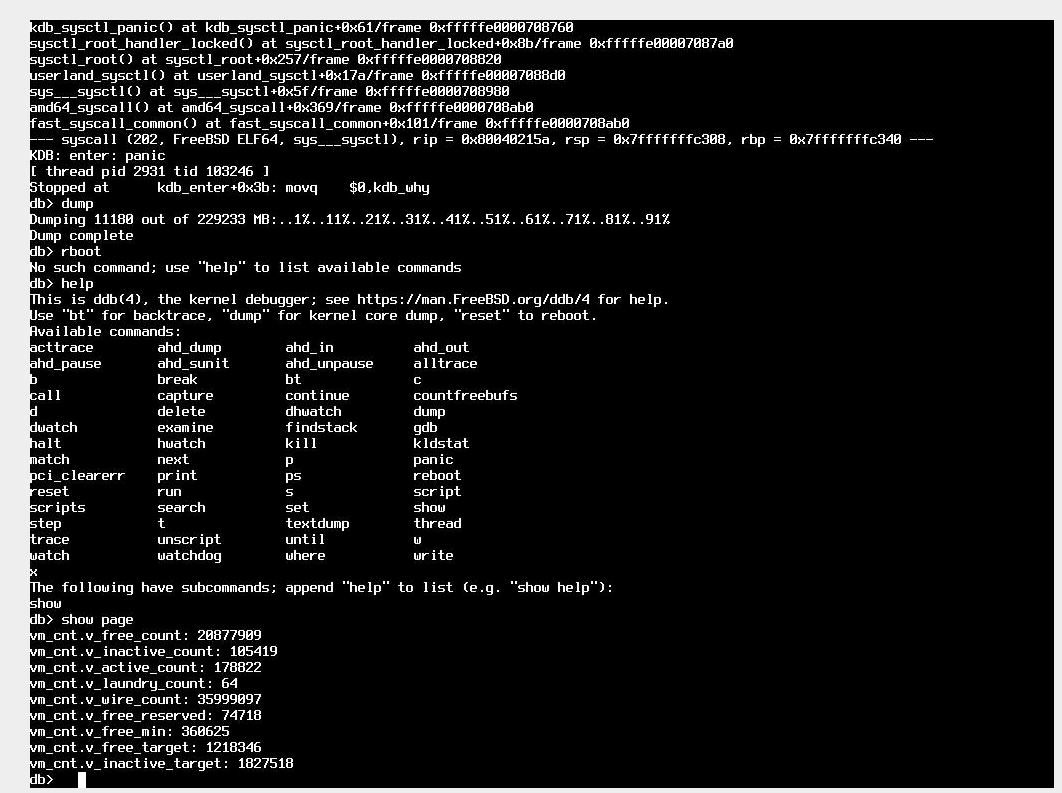
Comment Actions
This is the output from top -HSazo res when writes to ZFS stopped beeing processed on the system with a NUMA enabled kernel:
last pid: 2757; load averages: 0.09, 1.70, 1.48 up 0+00:57:34 16:28:50
2924 threads: 65 running, 2692 sleeping, 4 zombie, 163 waiting
CPU: 0.0% user, 0.0% nice, 0.0% system, 0.0% interrupt, 100% idle
Mem: 1069M Active, 19M Inact, 144K Laundry, 144G Wired, 73G Free
ARC: 139G Total, 41G MFU, 96G MRU, 2119M Anon, 311M Header, 23M Other
131G Compressed, 168G Uncompressed, 1.28:1 Ratio
Swap:
PID USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND
2316 root 20 0 1044M 1030M select 20 0:00 0.00% mbuffer -m1g -s128k{mbuffer}
2316 root 20 0 1044M 1030M piperd 47 0:19 0.00% mbuffer -m1g -s128k{mbuffer}
2316 root 21 0 1044M 1030M usem 44 0:11 0.00% mbuffer -m1g -s128k{mbuffer}
0 root -76 - 0 39M - 38 0:05 0.14% [kernel{if_config_tqg_0}]
0 root -76 - 0 39M - 0 0:00 0.01% [kernel{if_io_tqg_0}]
0 root -76 - 0 39M - 2 0:00 0.00% [kernel{if_io_tqg_2}]
0 root -76 - 0 39M - 4 0:00 0.00% [kernel{if_io_tqg_4}]
0 root -76 - 0 39M - 1 0:00 0.00% [kernel{if_io_tqg_1}]
0 root -76 - 0 39M - 48 0:00 0.00% [kernel{if_io_tqg_48}]
0 root -76 - 0 39M - 50 0:00 0.00% [kernel{if_io_tqg_50}]
0 root -76 - 0 39M - 60 0:00 0.00% [kernel{if_io_tqg_60}]
0 root -76 - 0 39M - 56 0:00 0.00% [kernel{if_io_tqg_56}]
0 root -76 - 0 39M - 54 0:00 0.00% [kernel{if_io_tqg_54}]
0 root -16 - 0 39M swapin 9 1:03 0.00% [kernel{swapper}]
0 root -76 - 0 39M - 6 0:00 0.00% [kernel{if_io_tqg_6}]
0 root -8 - 0 39M vmwait 9 0:39 0.00% [kernel{system_taskq_0}]
0 root -12 - 0 39M vmwait 63 0:11 0.00% [kernel{zio_write_issue_8}]
0 root -12 - 0 39M vmwait 56 0:11 0.00% [kernel{zio_write_issue_37}]
0 root -12 - 0 39M vmwait 56 0:10 0.00% [kernel{zio_write_issue_35}]
0 root -12 - 0 39M vmwait 50 0:10 0.00% [kernel{zio_write_issue_21}]
0 root -12 - 0 39M vmwait 47 0:10 0.00% [kernel{zio_write_issue_41}]
0 root -12 - 0 39M vmwait 40 0:10 0.00% [kernel{zio_write_issue_10}]
0 root -12 - 0 39M vmwait 37 0:10 0.00% [kernel{zio_write_issue_23}]
0 root -12 - 0 39M vmwait 2 0:10 0.00% [kernel{zio_write_issue_32}]
0 root -12 - 0 39M vmwait 21 0:10 0.00% [kernel{zio_write_issue_25}]
0 root -12 - 0 39M vmwait 18 0:10 0.00% [kernel{zio_write_issue_13}]
0 root -12 - 0 39M vmwait 48 0:10 0.00% [kernel{zio_write_issue_22}]
0 root -12 - 0 39M vmwait 37 0:10 0.00% [kernel{zio_write_issue_4}]
0 root -12 - 0 39M vmwait 29 0:10 0.00% [kernel{zio_write_issue_45}]
0 root -12 - 0 39M vmwait 63 0:10 0.00% [kernel{zio_write_issue_30}]
0 root -12 - 0 39M vmwait 16 0:10 0.00% [kernel{zio_write_issue_38}]
0 root -12 - 0 39M vmwait 1 0:10 0.00% [kernel{zio_write_issue_2}]
0 root -12 - 0 39M vmwait 41 0:10 0.00% [kernel{zio_write_issue_33}]
0 root -12 - 0 39M vmwait 38 0:10 0.00% [kernel{zio_write_issue_3}]
0 root -12 - 0 39M vmwait 25 0:10 0.00% [kernel{zio_write_issue_26}]
0 root -12 - 0 39M vmwait 2 0:10 0.00% [kernel{zio_write_issue_31}]
0 root -12 - 0 39M vmwait 38 0:10 0.00% [kernel{zio_write_issue_39}]
0 root -12 - 0 39M vmwait 4 0:10 0.00% [kernel{zio_write_issue_42}]
0 root -12 - 0 39M - 52 0:10 0.00% [kernel{zio_write_issue_40}]
0 root -12 - 0 39M vmwait 9 0:10 0.00% [kernel{zio_write_issue_43}]
0 root -12 - 0 39M vmwait 46 0:10 0.00% [kernel{zio_write_issue_36}]
0 root -12 - 0 39M vmwait 10 0:10 0.00% [kernel{zio_write_issue_1}]
0 root -12 - 0 39M vmwait 60 0:10 0.00% [kernel{zio_write_issue_34}]
0 root -12 - 0 39M vmwait 44 0:10 0.00% [kernel{zio_write_issue_9}]
0 root -12 - 0 39M vmwait 22 0:10 0.00% [kernel{zio_write_issue_24}]
0 root -12 - 0 39M vmwait 38 0:10 0.00% [kernel{zio_write_issue_12}]
0 root -12 - 0 39M vmwait 55 0:10 0.00% [kernel{zio_write_issue_46}]
0 root -12 - 0 39M vmwait 24 0:10 0.00% [kernel{zio_write_issue_7}]
0 root -12 - 0 39M vmwait 45 0:10 0.00% [kernel{zio_write_issue_19}]
0 root -12 - 0 39M vmwait 19 0:10 0.00% [kernel{zio_write_issue_5}]
0 root -12 - 0 39M vmwait 34 0:10 0.00% [kernel{zio_write_issue_14}]
0 root -12 - 0 39M vmwait 23 0:10 0.00% [kernel{zio_write_issue_20}]
0 root -12 - 0 39M vmwait 13 0:10 0.00% [kernel{zio_write_issue_18}]
0 root -12 - 0 39M vmwait 30 0:10 0.00% [kernel{zio_write_issue_15}]
0 root -12 - 0 39M vmwait 4 0:10 0.00% [kernel{zio_write_issue_28}]
0 root -12 - 0 39M vmwait 24 0:10 0.00% [kernel{zio_write_issue_0}]
0 root -12 - 0 39M vmwait 8 0:10 0.00% [kernel{zio_write_issue_11}]
0 root -12 - 0 39M vmwait 29 0:10 0.00% [kernel{zio_write_issue_17}]
0 root -12 - 0 39M vmwait 9 0:10 0.00% [kernel{zio_write_issue_16}]
0 root -12 - 0 39M vmwait 62 0:10 0.00% [kernel{zio_write_issue_27}]
0 root -12 - 0 39M vmwait 27 0:10 0.00% [kernel{zio_write_issue_6}]
0 root -12 - 0 39M vmwait 9 0:10 0.00% [kernel{zio_write_issue_47}]
0 root -12 - 0 39M vmwait 14 0:10 0.00% [kernel{zio_write_issue_44}]
0 root -12 - 0 39M vmwait 47 0:10 0.00% [kernel{zio_write_issue_29}]
0 root -16 - 0 39M - 42 0:09 0.00% [kernel{zio_write_intr_2}]
0 root -16 - 0 39M - 18 0:09 0.00% [kernel{zio_write_intr_3}]
0 root -16 - 0 39M - 48 0:09 0.00% [kernel{zio_write_intr_4}]
0 root -16 - 0 39M - 61 0:09 0.00% [kernel{zio_write_intr_7}]
0 root -16 - 0 39M - 4 0:09 0.00% [kernel{zio_write_intr_0}]
0 root -16 - 0 39M - 14 0:09 0.00% [kernel{zio_write_intr_5}]
0 root -16 - 0 39M - 17 0:09 0.00% [kernel{zio_write_intr_1}]
0 root -16 - 0 39M - 27 0:09 0.00% [kernel{zio_write_intr_6}]
0 root 8 - 0 39M - 58 0:05 0.00% [kernel{thread taskq}]
0 root -16 - 0 39M - 40 0:03 0.00% [kernel{zio_read_intr_0_10}]
0 root -16 - 0 39M - 7 0:03 0.00% [kernel{zio_read_intr_0_3}]
0 root -16 - 0 39M - 37 0:03 0.00% [kernel{zio_read_intr_0_2}]
0 root -16 - 0 39M - 14 0:03 0.00% [kernel{zio_read_intr_0_4}]
0 root -16 - 0 39M - 29 0:03 0.00% [kernel{zio_read_intr_0_0}]
0 root -16 - 0 39M - 32 0:03 0.00% [kernel{zio_read_intr_0_11}]
0 root -16 - 0 39M - 33 0:03 0.00% [kernel{zio_read_intr_4_2}]
0 root -16 - 0 39M - 4 0:03 0.00% [kernel{zio_read_intr_0_1}]
0 root -16 - 0 39M - 41 0:03 0.00% [kernel{zio_read_intr_4_11}]
0 root -16 - 0 39M - 45 0:03 0.00% [kernel{zio_read_intr_0_6}]
0 root -16 - 0 39M - 63 0:03 0.00% [kernel{zio_read_intr_4_4}]
...Comment Actions
Great, this helps. Finally, could I ask for output from "sysctl vm", again from the system in this state?
Comment Actions
That would be helpful. I'm on EFnet and freenode as markj; could you ping me on #bsddev on EFnet, #freebsd on freenode, or privately?
Comment Actions
I did and so far the system is usable after writing >300GB at best possible speed (before the problems would manifest around 70-80GB).
Update: With the patch from D17209 and a NUMA enabled kernel the system copied a 346GB dataset successfully.
Comment Actions
I have to revise my statement. I tried an other torture test (six dd if=/dev/zero bs=1m of=/kkdata/benchmark/$RANDOM writing to an uncompressed dataset). The system is still writing at about 1GB/s with the patch, but trying to exit some tools (e.g. zpool, top) hangs. Here is the procstat -kka output:
Comment Actions
I don't see any such processes in the procstat output. Did you try this test without "options NUMA"?
Comment Actions
Did you look at the zsh processes as well? I observed no hangs without "options NUMA".
Comment Actions
Yes, seems they're just waiting for children to report an exit status. I am wondering if the processes got swapped out. Could you provide "ps auxwwwH" output?
Comment Actions
I did see zsh processes wrapped with "<>" in top's output so they were get swapped out. I need a few minutes to reproduce the problem and run "ps auxwwwH".
Comment Actions
Peter reproduced this issue as well. I think the problem is with the vm_page_count_min() predicate in swapper_wkilled_only(). If one domain is depleted, we won't swap processes back in.
Comment Actions
I am not quite sure would could be an alternative there. if the policy for the kstack object is strict and corresponding domain is in severe low condition, then we must not start swapin.
I think that the current design does assume that all domains must return from the low conditions.
Comment Actions
Yes, and that assumption is not very ZFS-friendly, especially if the domain sizes are not roughly equal: the round-robin allocations performed in keg_fetch_slab() can cause the smaller domain(s) to become depleted, and we end up in a situation where one domain is permanently below the min_free_count threshold. Aside from causing hangs, this will also result in an overactive page daemon.
I think all of the vm_page_count_min() calls are problematic. For the swapper, at least, I think we need to follow r338507 and consult the kstack obj's domain allocation policy (as well as curthread's) before deciding whether to proceed. In other cases, such as uma_reclaim_locked(), the solution is not so clear to me. If we permit situations where one or more domains is permanently depleted, then uma_reclaim_locked() should only drain per-CPU caches when all domains are below the free_min threshold. However, this can probably lead to easy foot-shooting since it is possible to create domain allocation policies which only attempt allocations from depleted domains.
Comment Actions
Swapper then should collect all policies for kstack objects for all threads of the process which is swapped in. This is somewhat insane.
I think more reasonable approach is to always force the policy on creation of kstack obj, which allows fall to other domains, regardless of the current policy at the object creation time.
Comment Actions
Why "collect"? You can simply compare the domain set of each thread's policy to vm_min_domains in the FOREACH_THREAD_IN_PROC loop.
I think more reasonable approach is to always force the policy on creation of kstack obj, which allows fall to other domains, regardless of the current policy at the object creation time.
Ok, I will try this.
Comment Actions
I removed enough DIMMs to balance all four NUMA domains on my 32core EPYC system. Now each of the four domains contains a single 32GB DIMM for a total of 128GB. Under load (again multiple dd processes writing to ZFS) the system still swaps out complete processes (e.g. login shells running zpool iostat or top). If those processes exit and their parent shell was swapped out it can take over a minute until the shell is swapped back int although there are at least 3GB of free memory spread over all domains according to top.
While systems with unbalanced NUMA domains behave far worse the same problem exists in systems with balanced NUMA domains while top reported 3.8GB free memory.
Update: In one case it took over 7 minutes for zsh to get paged back in and execute date.