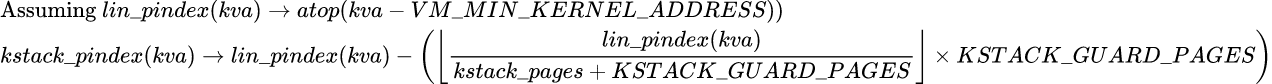This patch replaces the linear transformation of kernel virtual addresses to kstack_object pindex values with a non-linear scheme that circumvents physical memory fragmentation caused by kernel stack guard pages. The new mapping scheme is used to effectively "skip" guard pages and assign pindices for non-guard pages in a contiguous fashion.
This scheme requires that all default-sized kstack KVA allocations come from a separate, specially aligned region of the KVA space. For this to work, the patch also introduces a new, dedicated kstack KVA arena used to allocate kernel stacks of default size. Aside from fullfilling the requirements imposed by the new scheme, a separate kstack KVA arena has additional performance benefits (keeping guard pages in a single KVA region facilitates superpage promotion in the rest of the KVA space) and security benefits (packing kstacks together results in most kstacks having guard pages at both ends).
The patch currently enables this for all platforms, but I'm not sure whether this change would have a negative impact on fragmentation in the kernel's virtual address space when used on 32-bit machines. I'd be happy to change the patch so that this code is only used by 64 bit systems if need be.