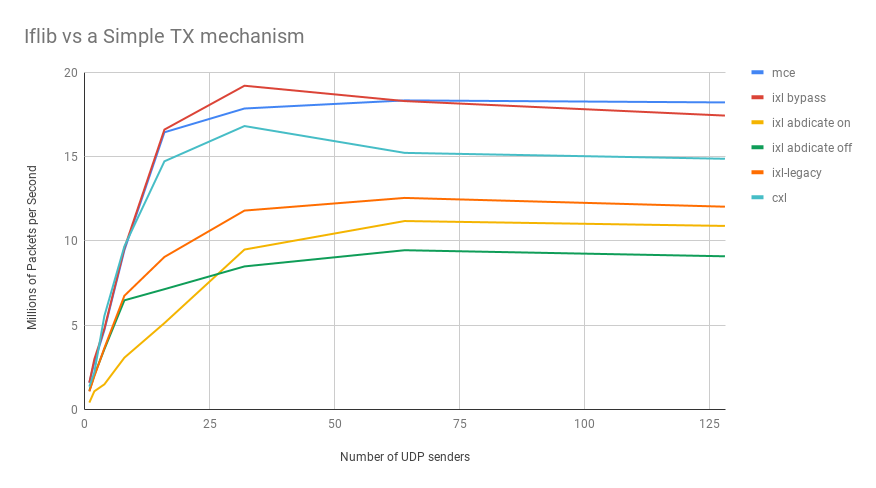
This is a quick hack that removes the mp_ring stuff from the
tx path for non-netmap only. Basically, it leaves the mp ring stuff
there, but bypasses it and calls the drain function directly.
This allows "easier" A/B testing.
To enable the hack, set dev.X.Y.iflib.bypass_mpring to non-zero in
loader.conf (cannot be changed after boot).
It would be nice to get other people to test this before the iflib
call.
THIS IS NEVER GOING TO BE COMMITTED IN THIS FORM!
If this pans out, pretty much all the txq stuff will be ripped out
and rewritten.