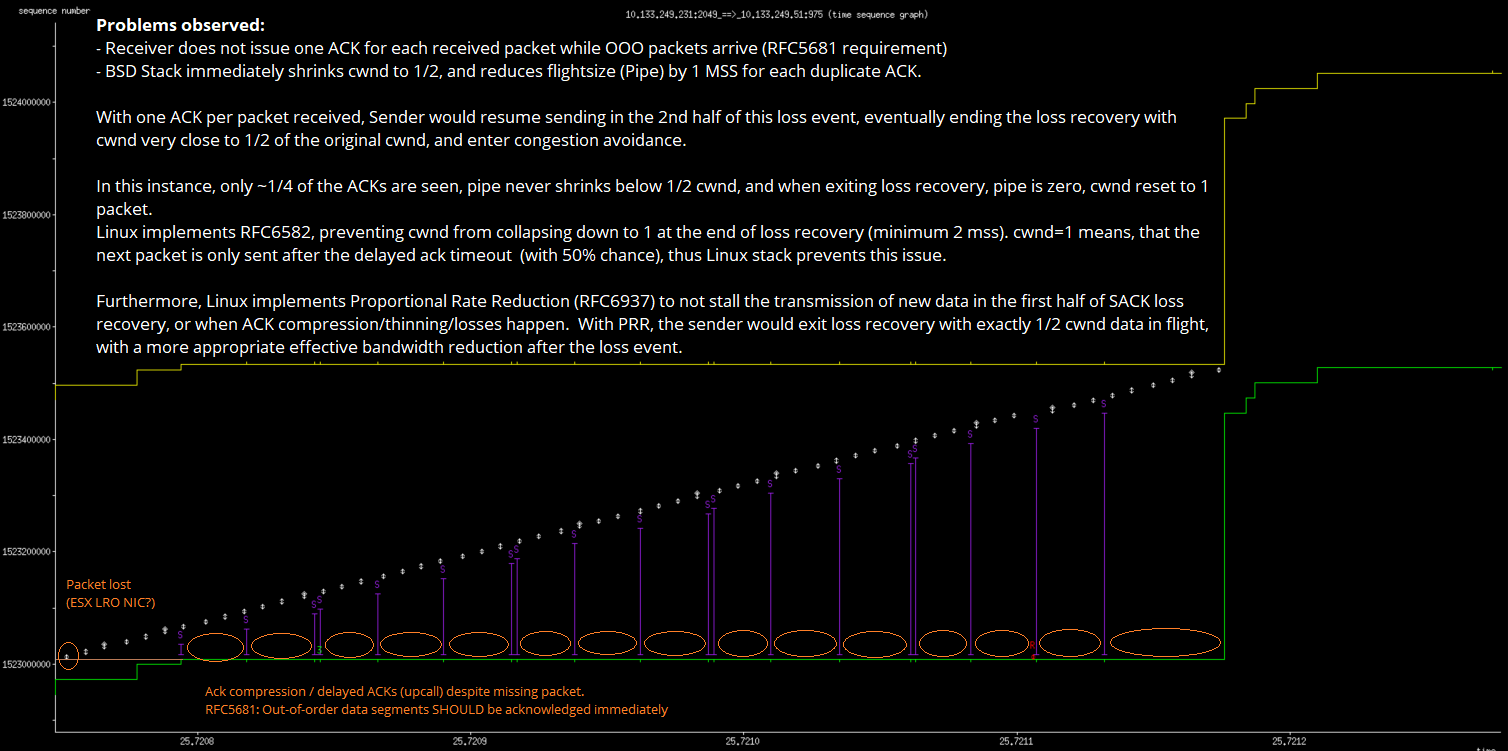
Under adverse conditions during loss recovery
- limited client receive window
- ACK thinning / ACK loss
- application limited (unsufficient data while in recovery)
pipe can collapse to very small levels, even down to 0 bytes.
RFC6582 is an adopted standards track RFC, updating RFC3782,
addressing this issue. With this patch, FreeBSD can claim compliance
with the more modern RFC
(see https://wiki.freebsd.org/TransportProtocols/tcp_rfc_compliance )