Running -j96 builds on a ThunderX.
Details
Details
Diff Detail
Diff Detail
- Repository
- rS FreeBSD src repository - subversion
- Lint
Lint Not Applicable - Unit
Tests Not Applicable
Event Timeline
Comment Actions
Are you referring to pde.mappings? We already have the rest:
[root@markj ~]# sysctl vm.pmap.l2 vm.pmap.l2.promotions: 35360 vm.pmap.l2.p_failures: 0 vm.pmap.l2.demotions: 5488
I meant to add it but forgot. Will fix.
Comment Actions
Yes. As a point of comparison, on HEAD/amd64, I see
18551.592u 1062.479s 56:55.94 574.1% 52924+3525k 52553+83337io 15368pf+0w
Mon Jul 16 22:34:55 CDT 2018
vm.pmap.pde.promotions: 61849
vm.pmap.pde.p_failures: 8440
vm.pmap.pde.mappings: 186494
vm.pmap.pde.demotions: 4125
vm.reserv.reclaimed: 0
vm.reserv.partpopq:
DOMAIN LEVEL SIZE NUMBER
0, -1, 245940K, 160
vm.reserv.fullpop: 118
vm.reserv.freed: 1242237
vm.reserv.broken: 0after a "buildworld". If I "force" almost all of clang's code to be superpages, I see
17938.868u 992.991s 55:29.09 568.6% 52934+3528k 51116+82109io 14078pf+0w
Tue Jul 17 12:28:43 CDT 2018
vm.pmap.pde.promotions: 61938
vm.pmap.pde.p_failures: 8348
vm.pmap.pde.mappings: 2674410
vm.pmap.pde.demotions: 4037
vm.reserv.reclaimed: 0
vm.reserv.partpopq:
DOMAIN LEVEL SIZE NUMBER
0, -1, 219356K, 130
vm.reserv.fullpop: 145
vm.reserv.freed: 1242232
vm.reserv.broken: 0(Forcing superpages means "clang -v; dd if=/usr/bin/clang of=/dev/null")
Comment Actions
I get:
vm.pmap.l2.promotions: 76312 vm.pmap.l2.p_failures: 0 vm.pmap.l2.mappings: 1603 vm.pmap.l2.demotions: 8526
and
vm.pmap.l2.promotions: 76205 vm.pmap.l2.p_failures: 23331119 vm.pmap.l2.mappings: 1778 vm.pmap.l2.demotions: 8855
respectively. I note that arm64 doesn't implement pmap_copy(). clang has the following program headers on this system:
[root@markj /usr/src]# readelf -l $(which clang)
Elf file type is EXEC (Executable file)
Entry point 0x10e0000
There are 9 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flg Align
PHDR 0x0000000000000040 0x0000000000010040 0x0000000000010040
0x00000000000001f8 0x00000000000001f8 R 0x8
LOAD 0x0000000000000000 0x0000000000010000 0x0000000000010000
0x00000000010c7ed8 0x00000000010c7ed8 R 0x10000
LOAD 0x00000000010d0000 0x00000000010e0000 0x00000000010e0000
0x0000000002813a44 0x0000000002813a44 R E 0x10000
LOAD 0x00000000038f0000 0x0000000003900000 0x0000000003900000
0x0000000000012530 0x0000000000296959 RW 0x10000
TLS 0x0000000003900000 0x0000000003910000 0x0000000003910000
0x0000000000001800 0x0000000000001820 R 0x10
GNU_RELRO 0x0000000003900000 0x0000000003910000 0x0000000003910000
0x0000000000002530 0x0000000000002530 R 0x1
GNU_EH_FRAME 0x00000000010b9248 0x00000000010c9248 0x00000000010c9248
0x0000000000002cdc 0x0000000000002cdc R 0x1
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0
NOTE 0x0000000000000238 0x0000000000010238 0x0000000000010238
0x0000000000000030 0x0000000000000030 R 0x4Comment Actions
lld has a curious default layout for arm64. A while back, I logged into the arm64 ref machine, and found that a bash executable compiled in, I believe, Feb had a text segment starting at 4M. However, newer executables aren't so nicely aligned, in other words, the initial R/O section doesn't start at a 2M boundary. That's why you're not getting a high mapping count.
Find the following line in kern_exec.c and replace 0 by 16.
vm_object_color(object, 0);
Comment Actions
That did the trick. Less than a minute into the build I see:
vm.pmap.l2.promotions: 1026 vm.pmap.l2.p_failures: 1 vm.pmap.l2.mappings: 16794 vm.pmap.l2.demotions: 47
Comment Actions
contrib/llvm/tools/lld/ELF/Arch/X86_64.cpp has
template <class ELFT> X86_64<ELFT>::X86_64() {
GotBaseSymOff = -1;
CopyRel = R_X86_64_COPY;
GotRel = R_X86_64_GLOB_DAT;
PltRel = R_X86_64_JUMP_SLOT;
RelativeRel = R_X86_64_RELATIVE;
IRelativeRel = R_X86_64_IRELATIVE;
TlsGotRel = R_X86_64_TPOFF64;
TlsModuleIndexRel = R_X86_64_DTPMOD64;
TlsOffsetRel = R_X86_64_DTPOFF64;
GotEntrySize = 8;
GotPltEntrySize = 8;
PltEntrySize = 16;
PltHeaderSize = 16;
TlsGdRelaxSkip = 2;
TrapInstr = 0xcccccccc; // 0xcc = INT3
// Align to the large page size (known as a superpage or huge page).
// FreeBSD automatically promotes large, superpage-aligned allocations.
DefaultImageBase = 0x200000;
}The corresponding file for AArch64 doesn't have a DefaultImageBase definition.
Comment Actions
Yufeng, see if you can post the clang/dhrystone png here. I suspect that Mark and Kostik will find it interesting.
Comment Actions
Couldn't we use the load address of the image to colour the object such that we don't rely on the linker providing a 2MB-aligned address?
Comment Actions
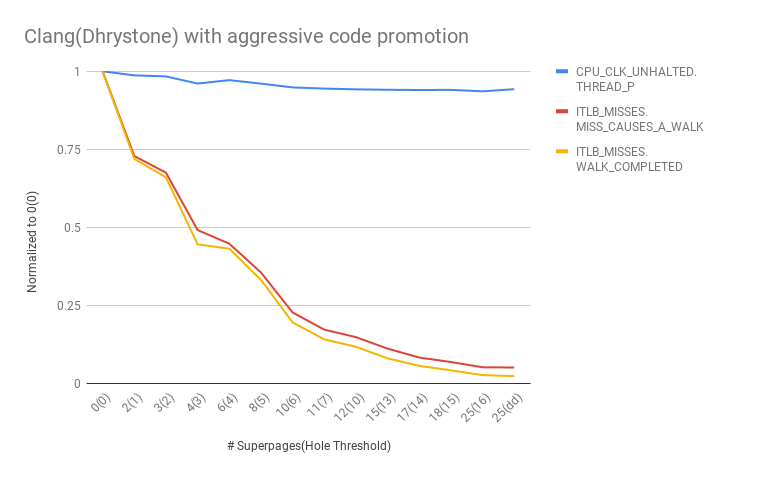
The patch we wrote allows the fault handler to fully populate and promote a reservation once the number of non-resident 64K-aligned chunks (aka "holes") in the reservation falls below some threshold. The test makes Clang compile Dhrystone for 5000 times. The following figure shows how three hardware counters change as we increase the threshold (and thus making the promotion policy more aggressive). The rightmost point on the x axis is where we apply the "dd if=/usr/bin/clang of=/dev/null" trick, and end up getting 25 superpages out of clang's main executable region.
Comment Actions
This is a chicken-or-the-egg problem. To determine the load address we have to read the headers from the file, but we have to allocate physical pages to hold the headers. But, for those physical pages to come from a reservation, we need to set the color before their allocation. The alternative is to do reallocation and copying. (Ick!)
Alternatively, we give up on a superpage mapping for the initial part of the file. Essentially, this is what the 0 -> 16 hack did. However, for clang, for example, there is a big promotable chunk of read-only data at the start of the file.
The current layout guarantees that we waste the first 16 PTEs in the L3 page table page and 64KB of virtual address space. Whereas, a 2MB-aligned layout would waste one PTE in the L2 page table page and 2MB of virtual address space. So, I don't really see a disadvantage to the 2MB-aligned layout.
Comment Actions
Diff'ing this pmap with amd64's also shows that it is missing reserve_pv_entries(). My recollection is that I had to add (and use) this function when I started implementing fine-grained PV list locking on amd64. And, arm64 has already replicated that fine-grained PV list locking ...
Comment Actions
Oops. I was also diff'ing arm/pmap-v6.c recently, and must have forgotten which diff I was looking at. :-)
Comment Actions
Somewhat, I read about it while researching the format of armv8 page table entries. It seems to allow one to exploit physical contiguity of a range of virtual pages such that the range requires only a single TLB entry, so quite similar to super pages but at a more fine-grained level. I could imagine using the reservation system to detect cases where we could use that attribute.
Comment Actions
Yes, exactly. I'm trying to figure out an incremental approach to implementing and testing use of ATTR_CONTIGUOUS. I speculate that step 1 is to teach pmap_{protect,remove}_l3() to recognize ATTR_CONTIGUOUS mappings and demote them, unless a range operation is being performed. I would not attempt to "coalesce" the 16 PV entries into one, just let them be. Then, step 2, the first use case, would be in pmap_enter_object(). When m->psind ==1 but the virtual address range isn't compatible with a 2MB mapping, use ATTR_CONTIGUOUS. This will, for example, be exercised by large, lld-generated executables, like clang, at the boundary between the ro segment and the executable segment.
Comment Actions
That sounds reasonable to me. I guess step 3 would consist of teaching pmap_enter() to check for an aligned, populated subrange of the reservation for the page, and promote the entries if so?
I think pmap_ts_referenced() will need some scheme for handling ATTR_CONTIGUOUS.
Comment Actions
Yes. And, as soon as I sent that last message, it occurred to me that pmap_enter() would need to be modified to demote ATTR_CONTIGUOUS mappings, e.g., COW faults.
I think pmap_ts_referenced() will need some scheme for handling ATTR_CONTIGUOUS.
Correct, and ultimately pmap_clear_modify().
P.S. Supposedly Zen/Ryzen does something like ATTR_CONTIGUOUS automatically, but the details on exactly what it does don't appear to be in the public documents, other than it's a 32 KB page size.
Comment Actions
It's called "PTE Coalescing". I've never found more than a 1-line description in slide decks from AMD, and a mention of being able to count 32 KB page L1 DTLB hits and misses in the open-source documentation for the performance counters. I'm trying to find out more ...