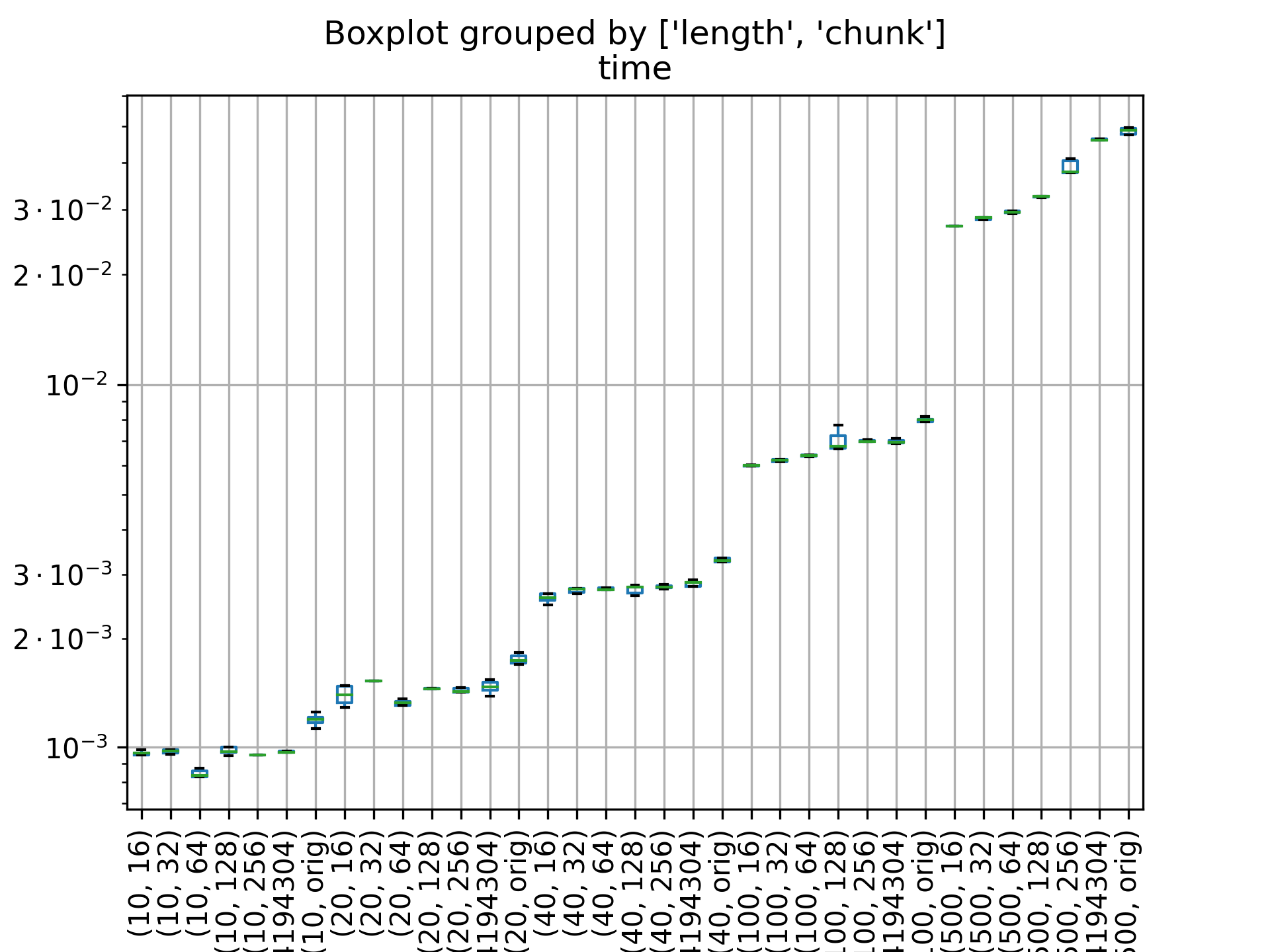
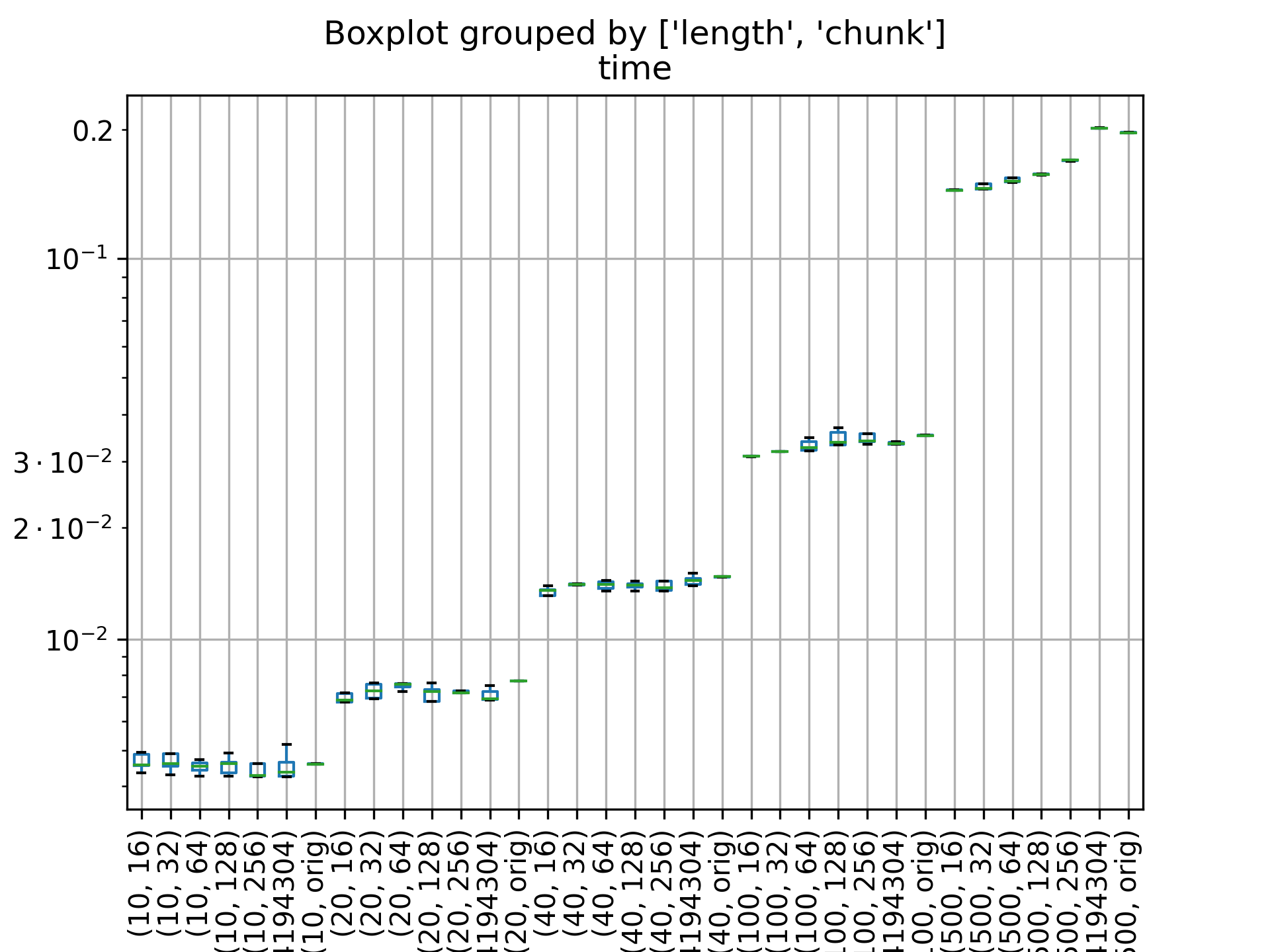
Every time sscanf is called, strlen is called... If the string is
long, maybe megabytes), but only a small part of the string is
consumed, we have geometric growth scanning the remaining, but never
parsed part of the string...
This breaks the string up into CHUNK_SIZE sized chunks, and only
verifies that a NUL is not in the chunk, before processing it...
This currently uses a hack by directly frobing fp->_p, but as we're
already munging the internals of the FILE, not a terrible solution..
allow redefining the chunk size to make it easier to benchmark..
wrapper memchr which has a better implementation than this...
This is only 30% slower than strlen (pre-asm version) on large strings
like 200k in size, rather than 600%...