Applied a patch that adds ranges support when the addresses of a CU is several discontinuous blocks.
Link to PR: https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=217736
Link to previous patch: https://sourceforge.net/p/elftoolchain/tickets/545/#6d97
Details
Details
- Reviewers
markj emaste - Commits
- rS357844: addr2line: Handle DW_AT_ranges in compile units
Tested against 10000 random addresses in the .so file provided by the patch contributor. Output is the same as GNU addr2line.
Diff Detail
Diff Detail
- Repository
- rS FreeBSD src repository - subversion
- Lint
Lint Not Applicable - Unit
Tests Not Applicable
Event Timeline
Comment Actions
In your testing, did you try passing -f or -i?
I have one general comment. I'm not a big fan of curlopc, I think it makes the code rather confusing. It's an optimization for the sorted case, but I'm not sure how much it actually helps. Can you provide some quick benchmark numbers to justify it? I also note that if the input is reverse-sorted, i.e., high addresses come first, then the curlopc optimization could make things slightly worse.
| contrib/elftoolchain/addr2line/addr2line.c | ||
|---|---|---|
| 451 ↗ | (On Diff #67871) | It looks like we do not do anything with off. Do we need it at all? |
| 461 ↗ | (On Diff #67871) | Uneeded parens. |
| 485 ↗ | (On Diff #67871) | break here? |
Comment Actions
r=reverse
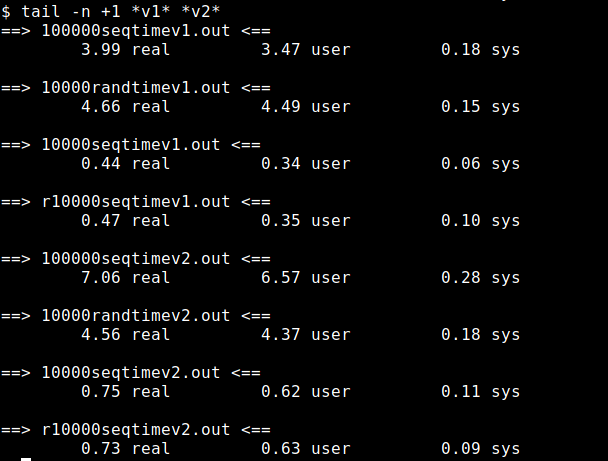
seq=sequential
rand=random
v1 is addr2line with curlopc
v2 is the version that resets cu to first cu for every translation
10000seq stores 10k sorted addr of first 20k kernel addr.
1000rand stores 1k rand addr in all of kernel addr
r10000seq is 10000seq reversed
Which version should I keep?
- I fixed the issues mentioned in the code comments.
- I tested the performance with curlopc and with resetting cu to first cu every time(v2), below is the results:
r=reverse
seq=sequential
rand=random
v1 is addr2line with curlopc
v2 is the version that resets cu to first cu for every translation
10000seq stores 10k sorted addr of first 20k kernel addr.
1000rand stores 1k rand addr in all of kernel addr
r10000seq is 10000seq reversed
Which version should I keep?
- I didn't test with -f -i before. And having tested it just now I realized the output between the old version and my patch looks different. I'm looking into it now.
Comment Actions
-f and -i flag outputs are now the same as original.
collect_func() needs gdb to get function name, so I added a field a CU to store this info in the cache.
Comment Actions
Ok. I am surprised that the difference is so substantial, and that curlopc helps even with reverse-sorted input. I think it is fine to keep it as-is then. I would still like to have a cleaner way to maintain a CU iterator, but I don't have any good suggestions at the moment.
| contrib/elftoolchain/addr2line/addr2line.c | ||
|---|---|---|
| 417 ↗ | (On Diff #67965) | I think a short comment explaining what this function does would be appropriate. |
Comment Actions
I added in line 482
if (lopc == curlopc) return (DW_DLV_ERROR);
for the case when DW_AT_Range is present so the program stops when we can't find an address.
This comment was removed by tig_freebsdfoundation.org.