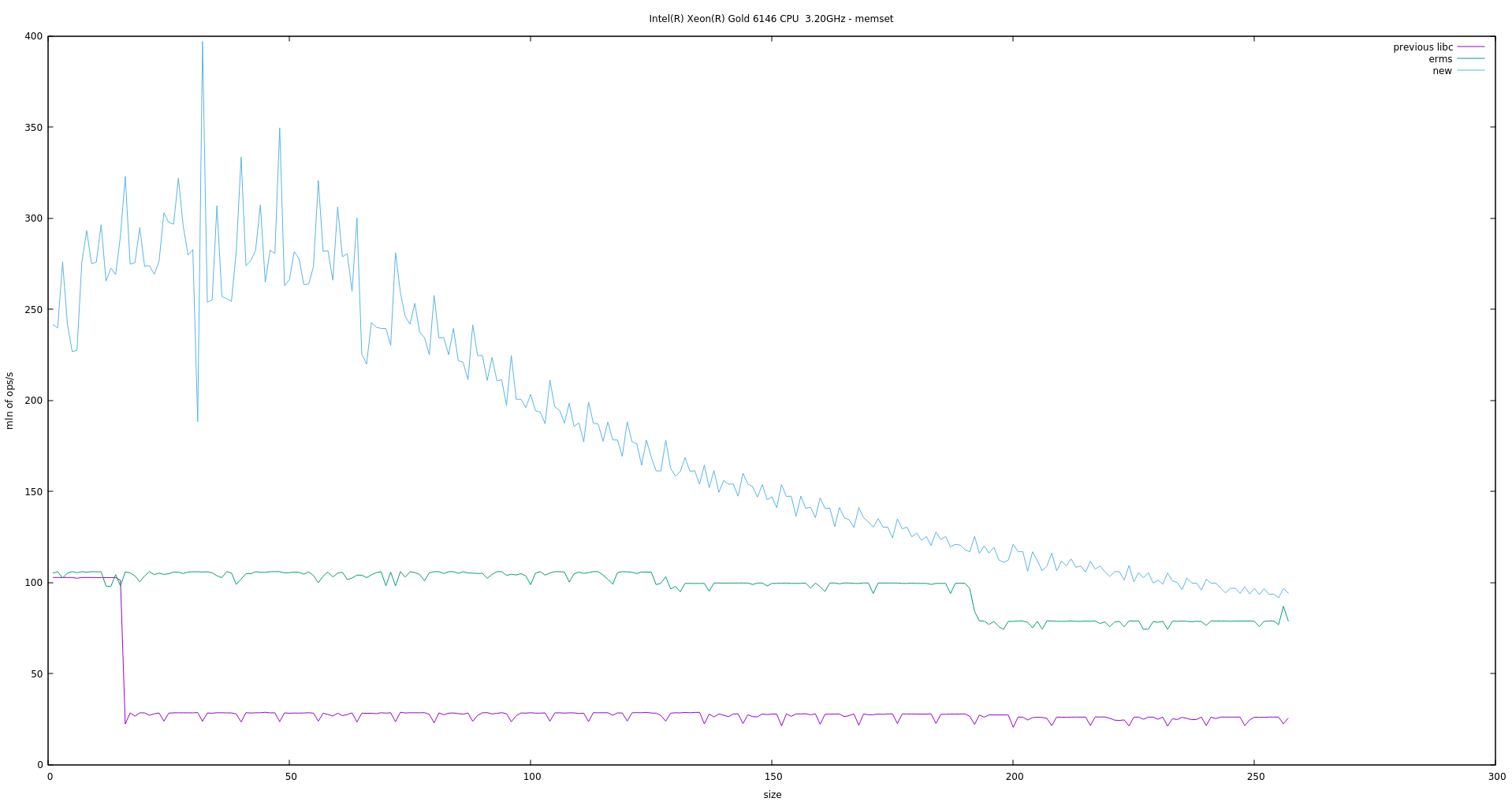
rep stos has a high startup time even on modern microarchitectures like Skylake. Intel optimization manuals discuss how for small sizes it is beneficial to go for streaming stores. Since those cannot be used without extra penalty in the kernel I investigated performance impact of just regular movs.
The patch below implements a very simple scheme: a 32-byte loop followed by filling in the remainder of at most 31 bytes. It has a 256 breaking point on which it falls back to rep stos. It provides a significant win over the current primitive on several machines I tested (both Intel and AMD). A 64-byte loop did not provide any benefit even for multiple of 64 sizes.
Note there is still room for improvement. I intend to bring it to libc later as a temporary bandaid until simd use can be implemented.
I graphed a very basic microbenchmark filling different sizes, 'previous libc' refers to the one present prior to recent replacement by the kernel variant.
{kind=link}