Turns out even very naive byte and 8 byte copy loops severely outperform ERMS-enabled CPUs. The patch below modifies memset, memmove and memcpy (copyin and copyout will be taken care of separately). Part of the goal is to get depessimized mid-point for libc before time can be spent trying to do anything fancy there. The cut off point of 128 is somewhat arbitrary, chances are solid it can be moved higher up with less naive loops. I did not play with alignment.
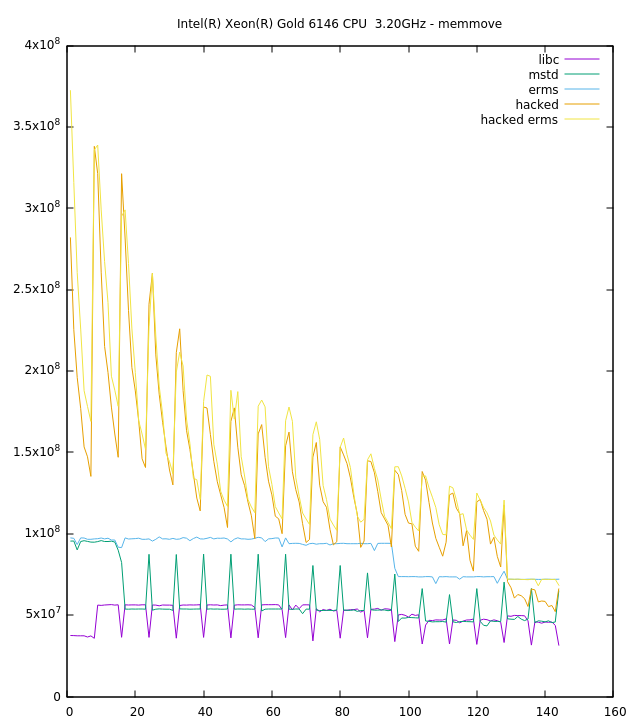
I benched memmove of sizes 0-144 on Ivy Bridge, Westmere, Broadwell, Skylake and EPYC (note 2 don't have ERMS) and all of them noted a marked improvement. Both target and source buffers were always aligned to 8 though.
Note there is still room for improvement, but this is a great stepping stone imho.
Below are results of hot cache memmoves in a loop from two boxes. x axis is number of bytes, left axis is ops/s. I did not scale units as they are not important (note ERMS results on EPYC are bad as expected since it does not have the bit).